On September 28th, the NBA Board of Governors approved changes to the NBA draft lottery system. These changes were construed in an attempt to help avoid tanking in the league in an effort to maximize a respective team’s probability of obtaining a high draft pick. In part, this is not a bad effort as we have seen great players do not necessarily go first in the draft. However, we’d like to take a look and see how much these changes actually affect teams. To do that, we take a look at the probabilistic structure of the NBA Draft Lottery.
The Draft is a Plackett-Luce Model
Anyone familiar with ranking algorithms are fully aware of the Plackett-Luce model. In case you’re not, here’s a brief synopsis.
Given a set of N items, consider each item having a probability of being selected. Let’s call this probability p_i. Here, i is the index of the item (one through N). Then, at random, an item is selected. Say item j is selected. Then we select an item from the remaining N-1 items; where item j is removed. This methodology is called sampling without replacement. This is the common “rank your favorite [sodas/TV shows/Presidential candidates] in order from most favorite to least favorite.”
Obtaining Probabilities of Orders
In terms of probabilities, let’s quickly write them out so we understand the process and can apply it to the NBA draft lottery. To begin, we must select a first team. This is given by

Here we assumed that Team_i was selected first. This is simply their own probability of selection. Next, we must select the second team. Since Team_i was already selected, there is zero probability of them being selected a second time. However, the total probability of a team being selected must be one. This means we normalize the probabilities by removing the first team’s probability via
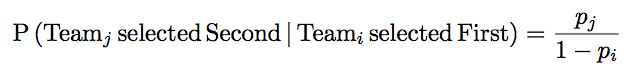
However, this is not our probability of seeing Team_j second! This is only seeing Team_j second only when Team_i is selected first! We will get to this in a moment.
For now, we have obtained the probability of seeing Team_i first and Team_j second. This is given by

We can continue this process to obtain the first four items of interest. To save space, let’s write ijkl to be Team_i selected first, Team_j selected second, Team_k selected third, and Team_l selected fourth. Then, the Plackett-Luce model is written as

This model yields the probability off seeing a certain ordering of items. However, this is not the probability we are usually interested in when it comes to the NBA Draft Lottery. Instead, we focus on the probability of obtaining a certain ranking.
Obtaining Probabilities of Ranks
To obtain a probability of ranks, we must compute the combinatorial problem of identifying all possible orderings. While this problem is simple for small samples such as NBA Draft Lotteries; this is considered the hardest problem in ranking as exhaustion is not feasible for more than 1,000 items! For 14 items, this is easy.
To obtain the probability of being first, we simply look at the sampling probabilities that are given to each item. For the NBA, this is
0.14, 0.14, 0.14, 0.125, 0.105, 0.09, 0.075, 0.06, 0.045, 0.030, 0.020, 0.015, 0.01, 0.005
with respect to teams one through 14. If we perform a quick check, these probabilities indeed sum to one. Therefore these are the probabilities of being selected for the first pick in the draft.
Now, what about being selected second in the draft? This problem is a little tougher. In this case, we must iterate through all possibilities of being selected second. For example, Team_j can be selected second only if Team_j is not selected first. In the case of the NBA Draft Lottery, there are only 13 possible scenarios of this happening. To calculate this probability for every team, however, we must perform 182 probabilistic computations. This is much larger than the 14 computations in finding the probability of being first for every team.
Now, to find that probability, we simply calculate

Let’s break this equation down. Here, p_j is the probability of selecting Team_j first! But wait… Team_j is selected second… This is true. We played a little manipulation game here. Let’s break this down completely.
The probability of selecting Team_j second given Team_i is selected first is
All we do is add these up for all teams that are not Team_j. This is where that sum with the i note equal to j term pops up. Since we are multiplying, we can do the a*b = b*a thing and swap p_i and p_j. Finally, since the sum only counts the teams selected first, and Team_j is not selected first, Team_j‘s probability can get pull out the sum. Voila!
If we want to compute this for being selected third or fourth, we can just continue the same process. For identifying the probability of being selected third for every team, we now must compute 2,184 probabilistic computations! The equation for Team_k being selected third is given by

You can see how this gets ugly pretty fast…
Coding Plackett-Luce in Python
Instead of trying to write out the probabilities by hand, we can write a simple algorithm that iterates through the combinations at a fast rate. There are many ways to go, such as building a function and iterating, iterating through every case, or building a recursive algorithm. Depending on the goal in mind, we select the method to do the job we wish to perform. For example, if we simply want to build a basic probability distribution, recursion works best. If we wish to incorporate trades; writing the entire structure out may be preferable.
First, we start with our initial probability vector. This is our sampling weights in terms of probabilities of being selected first in the draft.

We already know how to select the first team of the draft. Instead, we start with the second team in the draft.

Here we iterate through all possible teams as they are selected first. We remove their sampling probability, calling this firstRemoved and normalize the probabilities. This normalization is the 1-p_i that we need to compute. We simply generate the conditional probabilities of being selected second and add them up over all possible first round selections. This is performed using the zip command. Output of this function is given as

Yuck. If you can’t read that, it’s simply:
0.134, 0.134, 0.134, 0.122, 0.105, 0.092, 0.078, 0.063, 0.048, 0.033, 0.022, 0.017, 0.011, 0.006
These are indeed the probabilities of being selected second! Now we continue this iterative process to identify the third pick:

Notice that it is contained within the second pick’s block. This is because we must hold on to the second and first team when selecting the third team. Output for this is given by

Cleaning this up a bit, we have:
0.127, 0.127, 0.127, 0.119, 0.106, 0.094, 0.081, 0.067, 0.052, 0.036, 0.024, 0.019, 0.012, 0.006
This is indeed the probabilities for being selected third. Continuing this process, we obtain the probabilities for every team being able to obtain picks one through four:

Picks 5 through 14 are Deterministic
Once we select the first four teams, the remainder of the picks are deterministic. This means we know who, with certainty, selects fifth given knowledge of the first four teams. In the NBA Draft Lottery, this is the remaining team with the worst record. Recursively, the next team selected is the worst team of the remaining teams not selected.
What this means for our model is that we merely have to sum the instances of the first four picks and iterate through the teams remaining. There is no shuffling of probabilities as there are no more random draws. In Python, we can build a coding block that iterates this process.

Here, we enter in the probabilities for the remaining teams, called probs. The data structure remainingProbs is a 10-by-14 matrix where each row represents picks 5 through 14 in the draft and each column represents the team. The quantity restProb is the probability of selecting the first four teams in the draft.
What we are doing here taking the probability of seeing teams ijkl being selected for the first four picks and setting this restProb. We then iterate through who is left is order from worst team to best team. The nonzeros line identifies the teams remaining and the min() function finds the worst team remaining. At step i, we give that team the probability of having the ith pick, remove them for the next picks and repeat for the next worst team.
Within the Python code block, this function is called within the final code block after all four first teams are selected:

This gives us the overall structure of the NBA Draft Lottery.
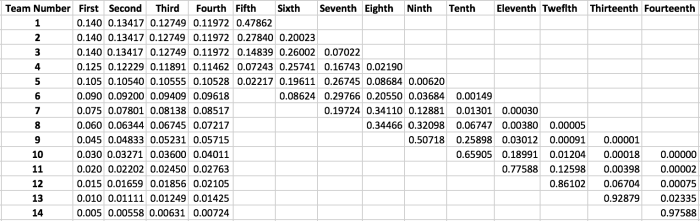
And there we have the entire NBA Draft Lottery odds for every team. More so, we have code to produce lottery odds whenever the lottery odds change. For instance, a tied team? Simply adjust the initialProbs vector and you’re done. A trade? Well, that’s a little more complicated.
Trades Can Be Accounted For…
If we recall the Sacramento Kings – Philadelphia 76ers pick swap from before, we can construct a new function in Python that performs a swap check. This is simple. We merely check for anytime the Kings were selected. Recall that every team is marked by their column. In the previous year, the Kings were the 8th team while the 76ers were the fourth team. This means the Kings are indexed as Team_7 while the 76ers are indexed as Team_3. This is due to indexing starting at zero. Every time a team is selected, we merely check if index 7 is deleted when index 3 exists. This would enforce a pick swap. We then swap the probabilities in secondProbs, thirdProbs, fourthProbs, or remainingProbs, depending where the swap occurs.
In the case a team not in the lottery obtains a pick. Consider last year the Chicago Bulls obtaining the rights to the Sacramento Kings pick if they fell below tenth in the Draft. In these cases, we have to make a slight adjustment to the probability vectors and include a fifteenth team with zero probability. We condition on a function of drop below tenth and add that probability into the fifteenth slot, which is held for the Bulls in this case.
Expected Draft Pick
Now that we have the distribution, we can compute the expected draft pick for each team. This is a simple process as we have the entire probability structure for every team in the Draft. The expected draft pick is the mean of the distribution for a team. We are used to the old “add the up values and divide by N” routine as kids. However, every probability is not the same and instead of multiplying by 1/N, we multiply by the probability of selection. In math terms, this is

For the worst team in the draft, this is given by
1*0.140 + 2*0.13417 + 3*0.12749 + 4*0.11972 + 5*0.47862 = 3.66279
This means that the team with the worst record is expected to obtain the 3.66279th pick in the draft. Continuing for every team in the draft, we obtain all the expected picks in the draft.

If we compare this to the previous version of the NBA Draft Lottery, we see that the lottery becomes more competitive for all teams.

Expected Lottery Picks for Each NBA Draft Lottery Team. Red is the current Draft format. Green is the Draft format starting in 2019. Blue is no lottery held.
Differences Between Now and 2019
The current draft lottery (pre-2019) gives a disincentive for teams that finish with the worst records by making their spots in the draft “up for grabs” by all teams in the draft lottery. Taking a look at the display of the expected draft positions, the blue line represents where a team should fall within the draft. This is the case where no lottery is held and teams pick based on order of worst to first.
Using a lottery, we deviate from this blue line. Anything above the blue line indicates a team’s chance of losing their spot in the draft, while anything below the blue line indicates that team having a better chance at advancing in the draft. The distance away from the blue line, the worse or better the team’s odds of losing their spot or gaining a spot, respectively.
In the current draft, only the worst three teams can lose their spot in the draft. The blue line and the red line intersect at the fourth spot in the draft. After that, the draft process benefits the other 10 teams. As the red line identifies the current expected values in the draft, there is not much deviation about the blue line. Let’s inject pick variation on each of these expected picks.

Current NBA Draft Lottery expected draft positions (red) compared to no lottery (blue). The red dashed lines indicate a single standard deviation of pick selection.
Here we see that only the first team in the draft is beaten up by the lottery process. Every other team falls relatively close to the No Lottery process. This indicates that the lottery does not really alleviate tanking as it’s effectively statistically equivalent to No Lottery.
What happens under the 2019 version?

Proposed NBA Draft Lottery expected draft positions (green) compared to no lottery (blue). The green dashed lines indicate a single standard deviation of pick selection.
In this case, we do negate some form of tanking as we see two teams pull off the blue line. Here, the fifth team is the cross-over point. This is due to the fourth draft position becoming a lottery draw.
While this does alleviate tanking to some degree, this new proposed methodology is not statistically different than the No Lottery version once again. What this effectively enforces is that teams should not tank into the bottom four spots; but rather the bottom five spots.
So how do we alleviate tanking? Make the entire lottery Plackett-Luce. Using the proposed probabilities, we should see both ends of the tail move away from the blue line. In this case, we will obtain significantly different than No Lottery odds while keeping a higher probability for worse teams to obtain that much needed draft pick.
However, at the same time, in doing this, there’s a large possibility of hurting smaller market teams that may get caught within picks 6-10 that may never find that diamond in the rough to pull them out of low-playoff/no-playoff limbo. How to quantify that, though, is a different story.




Pingback: How NBA Draft Lottery Probabilities Are Constructed by Justin Jacobs of Squared Statistics | Advance Pro Basketball
Hi there, i’m trying to coding your python examples but i have troubles with the line
” secondProbs = [x + y for x,y in zip(secondProbs,conditionalProbs)]”
I’m having the error :
NameError: name ‘secondProbs’ is not defined”
do you know how to correct it ? Thanks a lot !
LikeLike
Hello and welcome! You need to initialize the vector:
secondProbs = [0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,0.]
You will need to do this for all other levels beyond (thirdProbs, etc.).
The step that fails (zip command) is attempting to run the Plackett-Luce second selection model, which is a sum over all other first selection options.
Hope this helps!
LikeLike
Hi Squared,
Thanks for the great tutorial. I have a few questions.
I am able to get the first 4 picks running successfully. However, I am having trouble with the deterministic part. Where should I be defining the findFixedTeam function. if I put it after (and outside the loop) I get the error
remainingProbs = findFixedTeam(fourthRemoved,remainingProbs,restProb)
NameError: name ‘findFixedTeam’ is not defined
If I put it before the loop I get
File “main.py”, line 15, in findFixedTeam
team = min(nonzeros)
ValueError: min() arg is an empty sequence
I know that the 2nd half of that code (for l in range (14)) is nested within the rest of the loop.
I appreciate your help with this question.
LikeLike
Hello! Apologies for the errors you’re running into. Let’s try and see if we can fix them.
Set the findFixedTeam before the loop. It’s a user defined function that must exist before being called in the main function. So this means your error is attached to nonzeros being empty.
nonzeros is an array that is constructed using an enumeration function:
nonzeros = [j for j, e in enumerate(probs) if e != 0]
This means you likely have an empty vector being imported in as probs. At that particular line, this is the “fourthRemoved” vector. Can you check to see if it’s populated before calling:
remainingProbs = findFixedTeam(fourthRemoved,remainingProbs,restProb)
This is what I get for output::
[0.0, 0.14, 0.14, 0.125, 0.105, 0.09, 0.075, 0.06, 0.045, 0.03, 0.02, 0.0, 0.0, 0.0]
[0.14, 0.0, 0.14, 0.125, 0.105, 0.09, 0.075, 0.06, 0.045, 0.03, 0.02, 0.0, 0.0, 0.0]
[0.14, 0.14, 0.0, 0.125, 0.105, 0.09, 0.075, 0.06, 0.045, 0.03, 0.02, 0.0, 0.0, 0.0]
[0.14, 0.14, 0.14, 0.0, 0.105, 0.09, 0.075, 0.06, 0.045, 0.03, 0.02, 0.0, 0.0, 0.0]
[0.14, 0.14, 0.14, 0.125, 0.0, 0.09, 0.075, 0.06, 0.045, 0.03, 0.02, 0.0, 0.0, 0.0]
[0.14, 0.14, 0.14, 0.125, 0.105, 0.0, 0.075, 0.06, 0.045, 0.03, 0.02, 0.0, 0.0, 0.0]
[0.14, 0.14, 0.14, 0.125, 0.105, 0.09, 0.0, 0.06, 0.045, 0.03, 0.02, 0.0, 0.0, 0.0]
[0.14, 0.14, 0.14, 0.125, 0.105, 0.09, 0.075, 0.0, 0.045, 0.03, 0.02, 0.0, 0.0, 0.0]
[0.14, 0.14, 0.14, 0.125, 0.105, 0.09, 0.075, 0.06, 0.0, 0.03, 0.02, 0.0, 0.0, 0.0]
[0.14, 0.14, 0.14, 0.125, 0.105, 0.09, 0.075, 0.06, 0.045, 0.0, 0.02, 0.0, 0.0, 0.0]
[0.14, 0.14, 0.14, 0.125, 0.105, 0.09, 0.075, 0.06, 0.045, 0.03, 0.0, 0.0, 0.0, 0.0]
Hope this helps in diagnosis!
LikeLike
Hi Squared,
there was something going wrong with the loop that was running the “findFixedTeam” function. I changed the condition to “len(unique([i,j,k,l,m])) == 5:” (I am doing a 5 pick version) and my code now runs.
Thanks for your help.
LikeLike
I’m also having trouble with the deterministic portion, I continue getting this error:
File “nba_lottery.py”, line 49, in
remainingProbs = findFixedTeam(fifthRemoved, remainingProbs, restProb)
NameError: name ‘remainingProbs’ is not defined
Do I need to initialize remainingProbs, and if so, how? I tried to do that with:
remainingProbs = initialProbs[5:14]
If this is not the proper way to initialize remainingProbs, what is? Also, when I ran the code with this initialization, I ran into another error when calling on the function findFixedTeam:
File “nba_lottery.py”, line 16, in findFixedTeam
remainingProbs[i][team] = remainingProbs[i][team] + restProb
TypeError: ‘float’ object is not subscriptable
How should I change the code to avoid this?
Thanks for your time and help
LikeLike
Jeremiah,
That’s an interesting error. That error occurs if you are trying to grab the “ith position of a float.” This means that remainingProbs is returning a float instead of an array. I think this is happening because you are setting remainingProbs to be a single array. So when you attempt remainingProbs[i][team], you are grabbing the ith element of the array and then asking for the “team-th” element of the float; which is not subscriptable.
I initialize remainingProbs as a 10×14 matrix of all zeros.
Try using this initialization:
remainingProbs = [[0]*10 for _ in xrange(14)]
This should give you a 10×14 matrix of all zeros. The row is the draft pick, where row 0 is the 5th pick, and row 10 is the 14th pick. The column is a team identifier; which you will set as a dictionary.
Hope this helps!
LikeLike
Would you be able to elaborate on what you changed in the code to “len(unique([i,j,k,l,m])) == 5:” (I am interested in the four and five pick versions)? In my remainingProbs, I am getting very small values for the deterministic picks (6.54e-07), and my fourthRemoved variable only has three 0’s, not four as stated above. Lastly, I had to initialize the remainingProbs variable with remainingProbs = [[0]*11 for _ in xrange(14)] in order to avoid the IndexError: list index out of range. Any help would be greatly appreciated!
LikeLike
Thanks for the great post. It’s really helpful. Do you happen to have the python code available.
LikeLike
Alright I’ve initialized the remainingProbs properly now, but now the statement below returns 0:
remainingProbs[i][team] = remainingProbs[i][team] + restProb
Because it simply calls on a cell from the remainingProbs table, which we’ve set as all 0s. Should it be:
remainingProbs[i][team] = probs[i][team] + restProb ( for me, this results in the same ‘float’ object is not subscriptable error, because probs is fourthRemoved, which for me is [0.0, 0.0, 0.0, 0, 0.0, 0.09, 0.075, 0.06, 0.045, 0.03, 0.02, 0.0, 0.0, 0.0])
I also don’t understand how fourthRemoved could be the matrix you stated above (in your comment on 10/3). I have it being returned as a list of floats, since it’s populated by initialProbs, which is also a list of floats. If you could please elaborate on how to properly create fourthRemoved, I would really appreciate it!
Thanks again for your help, and I understand my comments may not be the easiest to understand what’s going wrong. I’m not getting errors and the code does properly run through, but doesn’t populate the remainingProbs table like your code does above, I’m still left with an empty remainingProbs matrix after the loop.
I appreicate you’re time and help!
LikeLike
Jeremiah,
Fourth removed isn’t a matrix, it’s an array that carried through a loop. We have to enumerate each option of all possible outcomes. So the code is walking through all 24,024 possible draft outcomes. What you see as a “matrix” (apologies for the confusion!) is really all the 11 different options of a team being selected fourth after teams 12, 13, and 14 have been selected as the first three picks. (This is the tail of the 24,024 outcome walk).
fourthRemoved is a vector with four of the entries being zero. These are the four teams selected for the first four picks. The rest are the probabilities of being selected.
nonzeros will identify the index of the team that has not been selected for the first four picks. If we run this on the first fourthRemoved vector, we get nonzeros = [1,2,3,4,5,6,7,8,9,10]. For the second fourthRemoved vector, we get nonzeros = [0,2,3,4,5,6,7,8,9,10], and so on…
team = min(nonzeros) just identifies the team with the highest probability that hasn’t been selected for a pick. This mimics the selection of that team in its deterministic spot. We then tack on the restProb for the team’s associated draft position using: remainingProbs[i][team] = remainingProbs[i][team] + restProb
restProb is a nonzero constant.
If you are still obtaining a zero, then this suggests that restProb is zero. From your fourthRemoved that is coming out, you have too many zeros. You have 8. There should only be 4.
LikeLike
Pingback: How NBA Draft Lottery Probabilities Are Constructed by 2020 squared stats – Advance Pro Basketball
I too am struggling with the deterministic portion.
line 11, in findFixedTeam
remainingProbs[i][team] = remainingProbs[i][team] + restProb
IndexError: list index out of range
I’ve initialized remainingProbs = [[0]*10 for _ in xrange(14)]
When I change it to remainingProbs = [[0]*11 for _ in xrange(14)], the code runs but returns a whole pile of zeros.
LikeLike
I encountered this similar problem at first, but later I realized we only need to swap 10 and 14, which now becomes [[0]*14 for _ in range(10)]. In this way we have a matrix of 10 rows and 14 columns. The reason behind this is that we initialized the list of probabilities for the first four picks with length of 14, so now each row means the probability each team gets a certain pick. Therefore, we need 14 columns instead of 10.
LikeLike
Is this code/program on GitHub or anywhere we could pull and run it?
LikeLike
Is this code/program on GitHub or somewhere we could pull and run it?
LikeLike
Thanks so much for posting this, it is a great explanation of the draft lottery process!
Could you please explain the math behind the 2nd seed having a 27.8% chance of getting the 5th pick? I can’t wrap my head around your code. The way I was thinking about it is the probability that the 2nd seed gets the fifth pick is the probability the first seed gets pick 1,2,3, or 4 AND the 2nd seed doesn’t get pick 1,2,3, or 4. However when I try to multiply those probabilities out, I don’t get 27.8%. Also, is your code available anywhere in github? Thank you so much, please let me know what you think!
LikeLike
Pranav, you should not expect to see a multiplicative event, due to the fact that team 1 being selected in the top four and team 2 not being selected in the top four is not independent. That’s a key item to note here. For instance knowledge of the 1 seed being in the top four picks changes the probability of the 2 seed being in the top four!
To compute the probability of the 2nd seed with the fifth pick, we first look at every option of Team 2 not being selected first. The crux of the work is being performed in the line secondProbs = [x + y for x,y in zip(secondProbs, ConditionalProbs)]. That’s updating the total probability of being selected second after the first pick is made. That is not creating a new vector each time. It is accumulating probability mass as the probability space is partitioned by Team 1 selected first, Team 2 selected first, Team 3 selected first, etc.
Now, we repeat this process for the first four picks. This will identify a nested loop of i,j,k,l of the first four picks. From there, we use the findFixedTeams probability. For the second team to be picked fifth, you need to walk through each combination to identify all partitions of Team 1 being selected in the Top 4 and Team 2 being selected outside of the Top 4. The code walks through each inner loop of the process.
I don’t supply the code explicitly because an Eastern conference team had an interview question asking to program this problem and asked me to not make this code available. I also don’t maintain a GitHub because of security clearance reasons: having an active GitHub requires continual pre-publication reporting.
LikeLike
My outputs for the deterministic part are coming out wrong, and I’m wondering what’s up. My output right now is: [[0.6061063372464911, 0.6061063372464911, 0.6061063372464911, 0.6380899685333511, 0.6843147158845073, 0.7218152974393464, 0.7618277994046502, 0.8043912727084909, 0.8495149815616888, 0.8971835351978165, 0.9303545730474919, 0.9469976599646707, 0.9471911845185329, 0], [0.6061063372464911, 0.6061063372464911, 0.6061063372464911, 0.6380899685333511, 0.6843147158845073, 0.7218152974393464, 0.7618277994046502, 0.8043912727084909, 0.8495149815616888, 0.8971835351978165, 0.9303545730474919, 0.9469976599646707, 0.9471911845185329, 0], etc (i dont need to post the whole thing but that’s just repeated)
This is my code:
for l in range(14):
if (i != l) and (j != l) and (k != l):
restProb = conditionalProbs3[l]
fourthRemoved = thirdRemoved[:l] + [0.] + thirdRemoved[l+1:]
remainingProbs = findFixedTeam(fourthRemoved, remainingProbs, restProb)
It’s nestled into the fourth pick code, like the others, and my function findFixedTeam is at the beginning:
def findFixedTeam(p, remainingProbs, restProb):
for x in range(10):
nonzeros = [j for j, e in enumerate(p) if e != 0]
team = min(nonzeros)
remainingProbs[x][team] = remainingProbs[x][team] + restProb
p[team] = 0.
return remainingProbs
Any ideas what’s wrong? Please let me know!
LikeLike
Pingback: NBA Draft
Pingback: NBA Draft – The Lottery
Do you happen to know how the NBA settled on the probabilities it came up with (…, 14, 12.5, 10.5, …)? Is it some well known algorithm?
I tried to replicate it by finding the midpoint of the non-top 3 teams, assigning that team a value of 1 then each team above or below it would get a value of 1+/- some #, say .23, multiplied by the previous value, and then for that team’s odds you’d just divide that team’s value divided by the total of all the values, multiplied by the remaining odds (.40=1-(.2*3)). Anyway, it came close, but not spot on and so now I’m stumped.
LikeLike
Hey Kieran! It’s an agreed upon value across the 30 teams. There may have been some algorithm to build those probabilities that we were unable to see; but it’s a hard-coded value from year to year.
I do know the equal probabilities for the bottom three teams was a direct result from thinking of ways to combat tanking. After that, I’m not 100% certain why they chose specifically the values they chose.
Sorry I can’t be much more help on that matter!
LikeLike