(Warning: Math Heavy)
The NFL has an adage: “Any given Sunday.”
This phrase typically means that during any week, for any given match-up between two teams, either team has a relatively high probability of winning the game. This translates into parity within the league. Typically we should see teams win between 6 and 10 games each season. The teams that are developed properly for the long haul (New England Patriots, Green Bay Packers, Pittsburgh Steelers) tend to sit on the upper end of the spectrum; while teams with sub-par front offices and an inability to consistently analyze talent in an adequate manner (Cleveland Browns, Oakland Raiders, Jacksonville Jaguars) will tend to be near the bottom of the standings each year.
The other teams tend to have a yo-yo effect. Some years are above-average with a possibility of making the playoffs; some years are below average. Teams tend to catch into this yo-yo effect due to several reasons such as free-agency, injuries, coaching adjustments, and pure luck of the draw in weather, referee assignments, or fan interaction.
In this article, we are going to take a look at the strength of schedule as determined by the quality of opponents, and determine which teams benefited due to their schedule. For instance, which 12-4 team was truly better: Denver Broncos, New England Patriots, or the Cincinnati Bengals? According to the NFL rules of tie-breakers, the Denver Broncos were the best team. The tie breaking procedures for determining the first through third seeds of the playoffs were as follows:
- Apply division tie breaker to eliminate all but the highest ranked club from each division prior to proceeding. Check. All teams from different divisions.
- Head-to-Head sweep. Only applicable if one of the three teams played the other two and won both games. Completed: Broncos defeated Patriots 30-24 (OT); Broncos defeated Bengals 20-17 (OT); both games in Denver. Denver Obtains #1 Seed.
- Head-to-Head, if applicable. Not applicable. Bengals did not play Patriots.
- Best won-lost-tied percentage in games played within conference. Patriots 9-3; Bengals 9-3.
- Best won-lost-tied percentage in common games; minimum of 4 games played. Patriots (4-1; Bills x2, Steelers, Broncos, Texans) , Bengals (2-3; Steelers x2, Broncos, Texans, Bills) – Patriots obtain 2 seed.
While the rules appear to be as close to fair as possible, the Patriots schedule appeared slightly easier than that Bengals as the Patriots as the Bengals’ opponents combined record is 122 – 134 compared to the Patriots’ opponents combined record of 121 – 135. Furthermore, the Bengals had to endure the NFC West compared to the Patriots’ run through the pitiful NFC East. While the basic numbers arguments can be made for the Bengals making a 2 seed over the Patriots, one thing is clear: neither team made the Super Bowl. Furthermore nothing changes the path to the Super Bowl going through Denver with the Patriots and Bengals swapping spots; provided either team defeated the Broncos on the road during the regular season.
On a similar note, the Carolina Panthers were consistently branded a weak and untested 15-1 team. Primarily due to their schedule. The Panthers started to quickly halt the nay-sayers with a first half drubbing of the Seattle Seahawks in the Divisional Round, followed by a blow-out of the Arizona Cardinals in the NFC Championship. With a stellar defense and a well-grounded (no pun intended) read-option game; the Panthers are poised to put up a strong fight against the turbulent Denver Broncos in Super Bowl 50.
So the question is, who will win Super Bowl 50? To answer that, we take a look at how the teams played throughout the season, how their opponents played, and how the playoffs were saddled due to the NFL rules. Would a Patriots-Bengals swap mattered? Does that increase or decrease the odds of the Broncos defeating the Panthers in a little more than a week?
First, we take a look at the continuity correction method for building a probability of winning a game. If we consider 
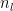


An estimate for 

 .
.
This implies that teams that have never played a game will be viewed as a “fifty-fifty” chance of winning games. As teams play, the probability of winning a random game moves in the direction of 1 or 0 in a conservative fashion.
Now that we have an (eighty year old) estimate for the probability of winning games, we then look at a clever way of writing a very simple number, identified by Colley (2002). From Colley, we can write the number of wins as
 .
.
This is the first step in writing the number of wins in a clever way. The second step is to note that
 .
.
This states that the total number of games is the same as adding 1 
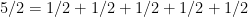
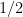
If we instead substitute in the probability of team 


 .
.
Once a series of games are played, we then must estimate the probabilities of winning games. This is a difficult task as a team’s probability of winning a game against a particular opponent is dependent on the opponent’s probability of winning that game; which is estimated from previous games with unknown probabilities. So we must pre-load a system of equations with unknown probabilities and solve for the unknown probabilities using linear algebra to estimate the probabilities.
To build the system of equations, we rewrite equation 2 by adding one to each side:

and then, by multiplying the left side by 1:
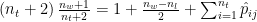 .
.
Note that 



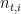

for 

That’s a lot of work, and it might even not look like an equation. But let’s consider what this looks like for one team in the league. Team 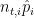


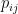
This is then a matrix called the Colley matrix, C, which has the values 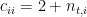



Now, there’s a subtlety here. If there are enough games, the matrix C is invertible. In Major League Baseball, the National Basketball Association, and the National Football League this is guaranteed true by season’s end. For NCAA Division I football, this is not the case. Thus the solution for r is either through matrix inversion of C or by using a pseudo-inverse.
As a quick, comparison of simple examples, let’s take a look at the Bay Valley Conference High School Basketball intra-conference rankings:
| School Name | *W-L | *Pct. | *PF | *PA | W-L | Pct. | PF | PA | Strk |
|---|---|---|---|---|---|---|---|---|---|
| Freedom | 4-0 | 1.000 | 274 | 204 | 15-4 | 0.789 | 1207 | 1042 | 4 W |
| Pittsburg | 3-1 | 0.750 | 229 | 215 | 13-7 | 0.650 | 1158 | 1054 | 1 W |
| Heritage | 2-2 | 0.500 | 282 | 272 | 16-4 | 0.800 | 1508 | 1212 | 1 L |
| Liberty | 2-2 | 0.500 | 267 | 285 | 15-5 | 0.750 | 1291 | 1135 | 1 L |
| Deer Valley | 1-3 | 0.250 | 266 | 274 | 10-9 | 0.526 | 1235 | 1191 | 1 W |
| Antioch | 0-4 | 0.000 | 203 | 271 | 4-16 | 0.200 | 1058 | 1211 | 10 L |
These are the games played only between the 6 teams in conference; in Contra Costa County, California, in the cities of Oakley (Freedom), Pittsburg, Brentwood (Liberty, Heritage), and Antioch (Deer Valley, Antioch). As we can see, this is a well-ordered standings. When we look at the wins-matrix, we have
| Freedom | Pittsburg | Heritage | Liberty | Deer Valley | Antioch | |
| Freedom | X | W | W | W | W | |
| Pittsburg | L | X | W | W | W | |
| Heritage | L | L | X | W | W | |
| Liberty | L | L | X | W | W | |
| Deer Valley | L | L | L | X | W | |
| Antioch | L | L | L | L | X |
The Colley matrix is then 


| Freedom | 0.8125 |
| Pittsburg | 0.6458 |
| Heritage | 0.5417 |
| Liberty | 0.4792 |
| Deer Valley | 0.3125 |
| Antioch | 0.2083 |
This ranking is exactly as we expect for the well-ordered set-up. Let’s take a look at another high school conference in California.
| School Name | *W-L | *Pct. | *PF | *PA | W-L | Pct. | PF | PA | Strk |
|---|---|---|---|---|---|---|---|---|---|
| Colony | 7-0 | 1.000 | 522 | 312 | 18-6 | 0.750 | 1634 | 1264 | 2 W |
| Ontario | 4-3 | 0.571 | 380 | 438 | 10-10 | 0.500 | 1107 | 1128 | 1 L |
| Alta Loma | 3-4 | 0.429 | 374 | 409 | 8-15 | 0.348 | 1168 | 1304 | 3 L |
| Montclair | 3-4 | 0.429 | 346 | 415 | 8-14 | 0.364 | 1220 | 1369 | 1 W |
| Don Lugo | 3-4 | 0.429 | 434 | 405 | 6-16 | 0.273 | 1337 | 1270 | 2 W |
| Chaffey | 1-6 | 0.143 | 346 | 423 | 4-17 | 0.190 | 1082 | 1284 | 4 L |
These are the games played only between the 6 teams in conference; in San Bernardino County, California, in the cities of Ontario (Colony, Ontario, Chaffey), Alta Loma, Montclair, and Chino (Don Lugo). Here, the standings are lot more muddled compared to the Bay Valley conference above. When we look at the wins-matrix, we have
| Colony | Ontario | Alta Loma | Montclair | Don Lugo | Chaffey | |
| Colony | X | WW | W | WW | W | W |
| Ontario | LL | X | W | L | W | WW |
| Alta Loma | L | L | X | LW | LW | W |
| Montclair | LL | W | WL | X | W | L |
| Don Lugo | L | L | WL | L | X | WW |
| Chaffey | L | LL | L | W | LL | X |
The matrix C is populated as:
| 9 | -2 | -1 | -2 | -1 | -1 |
| -2 | 9 | -1 | -1 | -1 | -2 |
| -1 | -1 | 9 | -2 | -2 | -1 |
| -2 | -1 | -2 | 9 | -1 | -1 |
| -1 | -1 | -2 | -1 | 9 | -2 |
| -1 | -2 | -1 | -1 | -2 | 9 |
The vector b is also [4.5, 1.5, 0.5, 0.5, 0.5, -1.5]’. Since the matrix, C, has rank 6, it is also invertible. This gives a solution of:
| Colony | 0.7715 |
| Ontario | 0.4657 |
| Montclair | 0.3980 |
| Alta Loma | 0.3574 |
| Don Lugo | 0.3243 |
| Chaffey | 0.0344 |
This suggests that despite the Mt. Baldy standings placing Alta Loma ahead of Montclair; Montclair has proven (only by wins and losses using the multinomial distribution for expected wins based on schedule strength) to be the stronger team in Mt. Baldy conference play.
Ranking the NFL Using the Colley Matrix
Now that we’ve seen how to use this common ranking method for separating out teams based on wins-losses and strength of schedule, we are able to apply the rankings method to the NFL. In this case, the matrix is 30×30 and the resulting rank of the matrix, C, is 30. The resulting rankings is then:
| Team | Ranking | AFC Playoffs | NFC Playoffs |
| Carolina | 0.8260 | 1st | |
| Arizona | 0.7892 | 2nd | |
| Denver | 0.7442 | 1st | |
| Cincinnati | 0.7243 | 3rd | |
| Minnesota | 0.7007 | 3rd | |
| Kansas City | 0.6868 | 5th | |
| New England | 0.6753 | 2nd | |
| Green Bay | 0.6643 | 5th | |
| Seattle | 0.6518 | 6th | |
| Pittsburgh | 0.6317 | 6th | |
| New York Jets | 0.5432 | ||
| Houston | 0.5229 | 4th | |
| Washington | 0.5115 | 4th | |
| Detroit | 0.5017 | ||
| St. Louis | 0.4899 | ||
| Buffalo | 0.4771 | ||
| Oakland | 0.4735 | ||
| Indianapolis | 0.4711 | ||
| Atlanta | 0.4646 | ||
| Chicago | 0.4524 | ||
| Philadelphia | 0.4289 | ||
| New Orleans | 0.4247 | ||
| San Francisco | 0.3882 | ||
| New York Giants | 0.3688 | ||
| Tampa Bay | 0.3573 | ||
| Baltimore | 0.3557 | ||
| Miami | 0.3402 | ||
| San Diego | 0.3182 | ||
| Jacksonville | 0.2860 | ||
| Dallas | 0.2802 | ||
| Cleveland | 0.2610 | ||
| Tennessee | 0.1890 |
Here, we see that the Carolina Panthers are indeed the top team in the NFL, according to the Colley ranking system. Furthermore, when the AFC and NFC playoff rankings are placed alongside the Colley rankings, we see that only the New York Jets are left out of the playoffs due to scheduling and NFL playoff ranking rules.
Now, using these rankings in the playoffs, we see that the Carolina Panthers and Denver Broncos tighten a little closer to each other, with Carolina still retaining the top spot. This indicates that the Carolina Panthers are expected to win the Super Bowl. Note that we stated expected; not predicted. This is in part due to the rankings model being an a posteriori model. That is, the model reflects only on the past.
For a predictive model, we may wish to break out a regression type method; such as multi-logit regression to reflect the updated probabilities. In doing this, based solely on wins-losses. This indicates that the Panthers have a 56% chance of winning the Super Bowl. We are unable to produce an expected score, as the model does not take scoring into account.
To take scoring into account, we use a Poisson regression model, which (using many more factors in this process) indicates that the Carolina Panthers should win the contest by a score of 34 – 20.